Die Webseiten der Fachschaft Informatik am ERG SaalfeldReguläre AusdrückeEs soll hier Schritt für Schritt die Nutzung von regulären Ausdrücken in Perl erklärt werden. Zum Nacharbeiten bzw. Wiederholen reicht es sicherlich, in der Zusammenfassung die benötigten Dinge zu suchen.
Bei der Verwendung von regulären Ausdrücken geht es darum, dass eine Regex auf einen String passt oder eben nicht.
Man sagt dann dazu, die Regex "matcht" mit dem String. Als Operator für das Binden an die Regex wird =~ verwendet.
Die Regex wird in 2 Slashs geschrieben. z.B. so: $string =~ m/^.*$/, das "m" vor den Slash bedeutet "matchen".
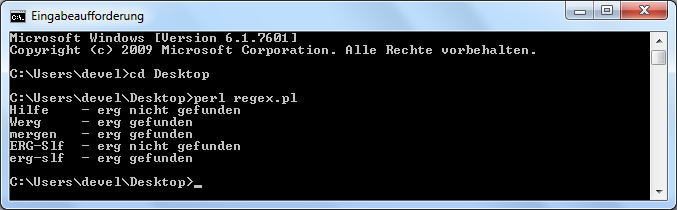
Wenn die Regex durch 2 Slashs begrenzt wird, kann das "m" weggelassen werden. einfache ZeichensucheBsp.: es sollen mehrere Strings daraufhin untersucht werden, ob sie die Buchstabenfolge 'erg' enthalten. Die Regex können wir so schreiben:
Suche nach SonderzeichenNach Zeichen, die in einer Regex eine besondere Bedeutung haben, kann nur dann gesucht werden, wenn man diese maskiert. Dazu wird vor diese Zeichen ein Backslash "\" gestellt. Solche Sonderzeichen sind: . ? * + ^ $ | \ / ( ) [ { Ein Beispiel (Suche nach zwei Slashs):
ZeichenklassenWir wollen aus einer Liste von Zeichen alle Zeichen herausfinden, die für römische Zahlen verwendet werden. Das sind M (für 1000), D (für 500), C (für 100), L (für 50), X (für 10), V (für 5) und I (für 1). Das bedeutet, wir suchen nach den Großbuchstaben M, D, C, L, X, V und I. Das schreibt man als Zeichenklasse so: [MDCLXVI]. Die Regex: bedeutet, dass das Zeichen auf eines dieser Buchstaben passt oder eben nicht. Wir wollen jetzt aus einer Liste von Strings alle zweistelligen Zahlen heraussuchen, die einen Tag angeben können. Da der Tag zweistellig ist, bedeutet das, er kann am Anfang eine 1 oder eine 2 oder eine 3 haben (der Januar hat ja z.B. 31 Tage). Die zweite Ziffer kann von 0 bis 9 gehen. Die Regex dazu kann man so schreiben: Das lässt sich auch so (kürzer) schreiben: Dadurch, dass der Bindestrich in einer Zeichenklasse eine Sonderbedeutung hat, muss ein Bindestrich, falls er zu den Zeichen einer Zeichenklasse gehören soll, entweder am Anfang oder am Ende geschrieben werden. z.B. so Diese Regex matcht, wenn es ein Kleinbuchstabe (von a bis z) oder ein Bindestrich ist. Die folgende Regex (mit Zirkumflex) bedeutet, dass nach allen Zeichen gesucht wird, die nicht auf einen Kleinbuchstaben oder einen Bindestrich passen. Das bedeutet, mit dieser Regex werden Ziffern, Großbuchstaben, Leerzeichen, Punkt, Semikolon u.a.m. gefunden.
Besondere ZeichenklassenFür häufig verwendete Zeichenklassen gibt es folgende Abkürzungen.
QuantorenEs wird in den seltensten Fällen nach einzelnen Zeichen gesucht, sondern nach Mustern aus mehreren/vielen Zeichen. Die Anzahl der Zeichen kann so angegeben werden:
AlternativenEine Zeile des Logfiles vom Webserver Apache im "common"-Format sieht z.B. so aus:
D.h. der Zeitpunkt wird so angegeben: 10/Oct/2000:13:55:36. Dabei ist "Oct" die Abkürzung für Oktober. Die Abkürzungen der anderen Monate sind: Jan, Feb, Mar, Apr, May, Jun, Jul, Aug, Sep, Oct, Nov, Dec. Wenn man nun die Zeilen heraussuchen will, die von den Monaten September bis November sind, dann sieht die Regex so aus: Allerdings wird die Regex nicht nur aus der Alternative bestehen, sodass man üblicherweise Klammern setzt.
AnkerpunkteWenn ein Muster in einer Zeile gesucht wird, kostet das deutlich mehr Zeit, als wenn die Regex "weiss", wo sie beginnen muss. Wenn also die Regex mit dem Beginn der Zeile bzw. des Strings matcht und das in der Regex auch angegeben wird, dann erhöht das die Performance beträchtlich. Um am Anfang der Zeile des Logfiles vom Apache (siehe letzter Punkt "Alternative") nach der IP am Anfang zu suchen, schreibt man das so:
Das bedeutet im Fall der Zeile des Logfiles, dass diese darauf geprüft wird, dass am Ende eine Zahl aus mindestens einer Ziffer steht.
OptionenOptionen dienen dazu das Verhalten unserer Regex zu verändern. Die Optionen werden hierbei hinter dem regulären Ausdruck angehängt. Es ist auch möglich mehrere Optionen zu benutzen, die Reihenfolge der Optionen spielt hierbei keine Rolle.
Es wird ein Treffer erzielt, wenn in der Zeile 'Sep' oder 'Oct' oder 'Nov' gefunden wird, wobei aber die Groß- und Kleinschreibung ignoriert wird. D.h. es wird auch 'sep' oder 'SEP' oder 'oCT' oder 'nov' oder 'noV' gefunden usw. Es soll jetzt nur eine Übersicht der Optionen angegeben werden (Kopie von wikibooks):
Ein Beispiel für die Option /x ist im nächsten Punkt zu finden.
Teilausdrücke merkenBis jetzt wurde immer das Muster als Ganzes betrachtet, entweder es hat gepasst (gematcht) oder eben nicht. Die wahre Leistung entfalten die regulären Ausdrücke aber dann, wenn man auf beliebige Teile des Musters zugreifen kann. Dazu werden runde Klammern verwendet. Auf den Teilausdruck in der ersten Klammer kann mit $1, auf den Teilausdruck in der zweiten Klammer kann mit $2, auf den Teilausdruck in der dritten Klammer kann mit $3, usw. zugegriffen werden. Es soll im Folgenden aus den Zeilen des Logfiles vom Webserver Apache die IP, das Login, das Datum und die Zeit herausgezogen werden. Dazu wird als erstes die Zeile des Logfiles mit Hilfe einer Regex beschrieben. Nochmal die Beispiel-Zeile des Logfiles:
Man kann den Anfang dieser Zeile so beschreiben:
^\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}\s+-\s\w+\s\[\d\d\/.{3}\/20\d\d\:..:..:..\s-?\d+\]\s\"
^(\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3})\s+-\s(\w+)\s\[(\d\d\/.{3}\/20\d\d\):(..:..:..)\s-?\d+\]\s\"
Capturing vs. ClusteringWie im letzten Abschnitt "Teilausdrücke merken" angegeben, werden Klammern verwendet, um Teilstrings festzuhalten (Capturing). Im Abschnitt "Alternativen" wurde angegeben, dass man bei Alternativen üblicherweise Klammern verwendet, um diese zu gruppieren (Clustering). Im "Kamel-Buch" (Programmieren mit Perl) steht das so (siehe Weblinks):
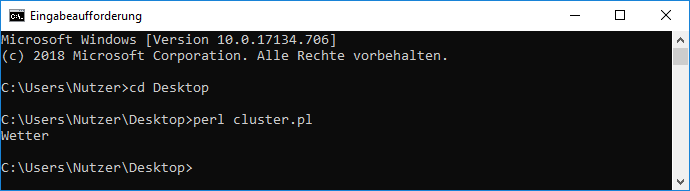
Ein Beispiel: Wir suchen nach einem Substantiv und wissen, dass davor ein Artikel steht. Der Artikel interessiert uns nicht, sondern nur das Substantiv. Oder anders gesagt, das Substantiv wollen wir uns merken, den Artikel nicht. Das läßt sich so schreiben:
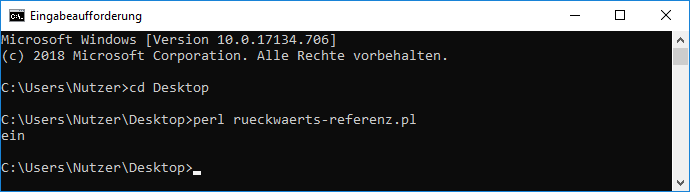
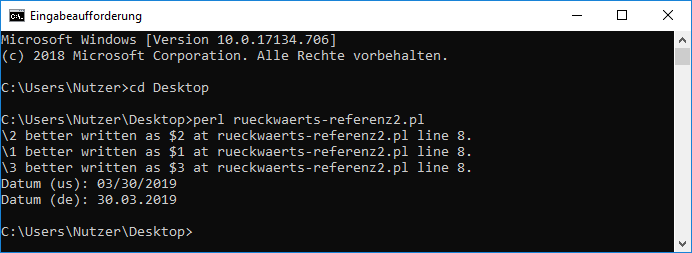
Teilausdrücke rückwärts referenzieren"Möchte man sicherstellen, dass ein gefundener Teilausdruck genau so nocheinmal im durchsuchten Text zu finden ist, kann man Rückreferenzen benutzen." (aus einer Mail der Mailingliste der Frankfurter Perl-Mongers von Renée Bäcker) Um das 1 : 1 in ein Programm zu gießen, sei ein Satz (String) gegeben und in diesem sollen Wörter gefunden werden, die mehrfach vorkommen. Häufig kommt folgender Tippfehler vor, dass ein Wort unabsichtlich doppelt geschrieben wird. Der Einfachheit halber wird hier davon ausgegangen, dass das Wort nur aus Buchstaben, dem Unterstrich und Ziffern besteht. Dann läßt sich das Wort so als Regex schreiben: (\w+) . Damit auch bestimmt ein ganzes Wort genommen wird, rahmen wir diesen kleinen regulären Ausdruck durch den Wortbegrenzer \b ein. Damit sieht die Regex für ein Wort jetzt so aus: \b(\w+)\b . Danach sollen bzw. können beliebige Wörter und Zeichen kommen, also einfach .* und dann soll das stehen, was durch den ersten Ausdruck, also die Klammer, gefunden wurde. Dafür steht die \1 für den ersten gefundenen Ausdruck. Allerdings würde sich dann auch ein Treffer ergeben, wenn dieses Wort nur ein Teil des zweiten Wortes wäre. Es geht aber hier darum, dass das Wort zweimal (gleich) geschrieben wurde. Also sieht der Suchausdruck bei mir so aus: \b(\w+)\b.*\b\1\b (Dieses Beispiel wurde mir aus der Mailingliste der Frankfurter Perl-Mongers von Wieland Pusch angegeben.)
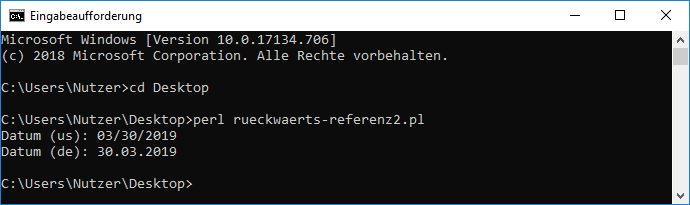
$datum_im_de_format =~ s|(\d\d)/(\d\d)/(\d\d\d\d)|$2.$1.$3|; dann verschwinden die Warnungen. Bedeutet: das in der Wikipedia angegebene Beispiel ist kein wirkliches Beispiel für Rückwärtsreferenzen (zumindest nicht für Perl). Merke: Rückwärtsreferenzen sollten nur im Suchteil verwendet werden.
GierBei der Verwendung von runden Klammern, um Teilausdrücke zu merken (siehe Punkt 9) oder rückwärts zu referenzieren (siehe Punkt 11) kommt es häufig vor, dass es mehrere Möglichkeiten gibt, die auf die geklammerten Ausdrücke in der Regex passen. Damit ergibt sich die Frage, "welcher Teilausdruck wird dann durch die Regex gefunden?". Ein Beispiel: in dem Logfile sollen alle HTML-Seiten herausgefiltert werden. HTML-Seiten enden auf 'html' oder 'htm'. Man kann das durch folgende Regex beschreiben: ^[^"]+\"\[A-Z]+\s(.*\.html?)\s Bedeutet: vom Anfang solange weiter gehen, wie es kein Anführungszeichen ist, dann ein Anführungszeichen, dann ein Wort aus Großbuchstaben, dann ein Leerzeichen, dann der Dateiname, der auf .html oder .htm endet. Das Programmfragment zum Finden des Dateinamens würde dann so aussehen: Für die Zeile
stellt sich die Frage: steht in dem Klammerausdruck nun /index.html oder /index.htm ? Die Antwort lautet: /index.html ! Merke: die Regex findet von den passenden Ausdrücken immer den größten! - man sagt auch: die Regex ist gierig.
Weblinks
© ERG Saalfeld - Hans-Dietrich Kirmse 14.05.2019 |