Die Webseiten der Fachschaft Informatik am ERG Saalfeld
Reguläre Ausdrücke
Diese Seite ist die Portierung der Seite zur Verwendung von regulären Ausdrücken in Perl. Die Lösungen in Python wurden
durch Moritz Thomae bereitgestellt.
Es soll hier Schritt für Schritt die Nutzung von regulären Ausdrücken in Python erklärt werden.
- einfache Zeichensuche
- Suche nach Sonderzeichen
- Zeichenklassen
- Besondere Zeichenklassen (z.B. \w)
- Quantoren
- Alternativen
- Ankerpunkte (hier nur Zeilenanfang und -ende)
- Optionen
- Teilausdrücke merken
- Gier
- Funktionen des Moduls 're' zur Nutzung der reulären Ausdrücke
Bei der Verwendung von regulären Ausdrücken geht es darum, dass eine Regex auf einen String passt oder eben nicht.
Man sagt dann dazu, die Regex "matcht" mit dem String. Während in Perl reguläre Ausdrücke praktisch (fast) an jeder Stelle des Scriptes
genutzt werden können (quasi als Sprache in der Sprache), wird in Python das re-Modul genutzt. Dieses Modul stellt als Interface
eigene Befehle zur Nutzung für die Regexe zur Verfügung, wie z.B. split, search und match.
einfache Zeichensuche
Bsp.: es sollen mehrere Strings daraufhin untersucht werden, ob sie die Buchstabenfolge 'erg' enthalten.
Wir nutzen den search-Befehl. Die Regex ist der String "erg" und wir schreiben das so: re.search("erg", string) ,
wobei string die String-Variable ist, mit der die Regex 'erg' matchen soll.
Wenn die Regex passt (matcht), dann soll ausgegeben werden: 'erg' gefunden, sonst: 'erg' nicht gefunden.
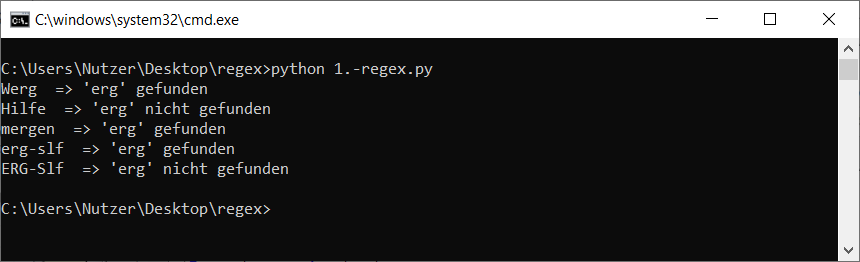
Das Programm sieht dann z.B. so aus:
import re
liste = ["Werg", "Hilfe", "mergen", "erg-slf", "ERG-Slf"]
for string in liste:
if (re.search("erg", string)):
print(string, " => 'erg' gefunden")
else:
print(string, " => 'erg' nicht gefunden")
Der Aufruf sah dann bei mir so aus:
Suche nach Sonderzeichen
Nach Zeichen, die in einer Regex eine besondere Bedeutung haben, kann nur dann gesucht werden, wenn man diese maskiert.
Dazu wird vor diese Zeichen ein Backslash "\" gestellt. Solche Sonderzeichen sind: . ? * + ^ $ | \ ( ) [ ] { }
Ein Beispiel: um nach nach einen Fragezeichen zu suchen (hier in einer URL mit einem Script), muss dieses Fragezeichen als Sonderzeichen maskiert
werden, d.h. ein Backslash vorangestellt werden. Also so: \? . (Anmerkung: ohne dem Backslash gibt es eine Fehlermeldung.)
Der search-Befehl sieht dann so aus: re.search("\?", string) .
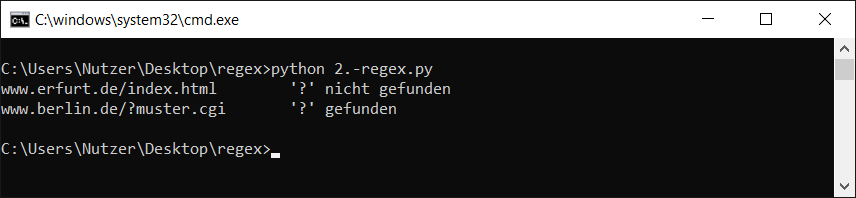
Auch hier ein Beispielprogramm dazu:
import re
liste = ["www.erfurt.de/index.html", "www.berlin.de/?muster.cgi"]
for string in liste:
if (re.search("\?", string)):
print(string, "\t", "'?' gefunden")
else:
print(string, "\t", "'?' nicht gefunden")
Der Aufruf sah dann bei mir so aus:
Die Verwendung von raw-Strings
Prinzipiell werden reguläre Ausdrücke in Python als Strings dargestellt.
Bei Strings werden aber Backslashes als Escape-Zeichen benutzt. Das bedeutet aber, dass sie mit dem
folgenden Zeichen einer Sonderbedeutung zugeführt werden.
Sie können in Python eine Rohzeichenfolge erstellen, indem Sie einem Zeichenfolgenliteral r oder R voranstellen.
Die Python-Rohzeichenfolge behandelt den umgekehrten Schrägstrich (\) als Literalzeichen. Raw-String ist nützlich,
wenn ein String einen umgekehrten Schrägstrich enthalten muss, z. B. für einen regulären Ausdruck oder einen
Windows-Verzeichnispfad, und Sie nicht möchten, dass er als Escape-Zeichen behandelt wird.
Quelle: siehe Weblink 1
Empfehlung: Der String für die Regex sollte immer als raw-String angegeben werden.
Als nächstes Beispiel suchen wir nach einem Tabulator. Der search-Befehl sieht jetzt so aus: re.search(r"\t", string) .
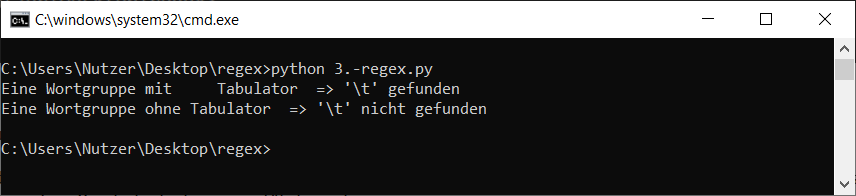
Und auch für dieses Beispiel das Programm:
import re
liste = ["Eine Wortgruppe mit\tTabulator", "Eine Wortgruppe ohne Tabulator"]
for string in liste:
if (re.search(r"\t", string)):
print(string, " => '\\t' gefunden")
else:
print(string, " => '\\t' nicht gefunden")
Der Aufruf sah dann bei mir so aus:
Zeichenklassen
Wir wollen aus einer Liste von Zeichen die Zeichen herausfinden, die für römische Zahlen verwendet werden.
Das sind M (für 1000), D (für 500), C (für 100), L (für 50), X (für 10), V (für 5) und I (für 1). Das bedeutet, wir suchen
nach den Großbuchstaben M, D, C, L, X, V und I. Das schreibt man als Zeichenklasse so: [MDCLXVI]. Die Regex (als raw-String):
regex = r"[MDCLXVI]"
re.search(regex, string) bedeutet, dass das Zeichen auf eines dieser Buchstaben von string passt oder eben nicht.
Wir wollen jetzt aus einer Liste von Strings alle zweistelligen Zahlen heraussuchen, die einen Tag angeben können.
Da der Tag zweistellig ist, bedeutet das, er kann am Anfang eine 1 oder eine 2 oder eine 3 haben (der Januar hat ja z.B. 31 Tage).
Die zweite Ziffer kann von 0 bis 9 gehen. Die Regex dazu kann man so schreiben:
regex = r"[123][0123456789]"
Das lässt sich auch so (kürzer) schreiben:
regex = r"[1-3][0-9]"
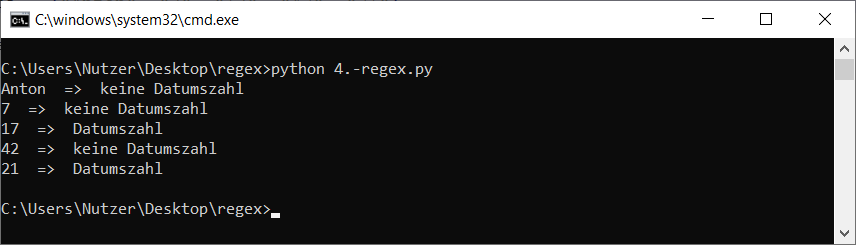
Wiedermal ein Beispielprogramm dazu:
import re
liste = ["Anton", "7", "17", "42", "21"]
regex = r"[1-3][0-9]"
for string in liste:
if (re.search(regex, string)):
print(string, " => Datumszahl")
else:
print(string, " => keine Datumszahl")
Der Aufruf sah dann bei mir so aus:
Dadurch, dass der Bindestrich in einer Zeichenklasse eine Sonderbedeutung hat, muss ein Bindestrich, falls er zu den
Zeichen einer Zeichenklasse gehören soll, entweder am Anfang oder am Ende geschrieben werden. z.B. so:
regex = r"[a-z-]"
Diese Regex matcht, wenn es ein Kleinbuchstabe (von a bis z) oder ein Bindestrich ist.
Die folgende Regex (mit Zirkumflex)
regex = r"[^a-z-]"
bedeutet, dass nach allen Zeichen gesucht wird, die nicht auf einen Kleinbuchstaben oder einen Bindestrich passen.
Das bedeutet, mit dieser Regex werden Ziffern, Großbuchstaben, Leerzeichen, Punkt, Semikolon u.a.m. gefunden.
Besondere Zeichenklassen
Für häufig verwendete Zeichenklassen gibt es folgende Abkürzungen.
| Zeichen |
Entsprechung |
Bedeutung |
| \d |
[0-9] |
Ziffer |
| \D |
[^0-9] |
Gegenstück zu \d |
| \w |
[a-zA-Z_0-9] |
Buchstabe, Unterstrich oder Ziffer |
| \W |
[^a-zA-Z_0-9] |
Gegenstück zu \w |
| \s |
[ \t\n\f\r] |
Whitespace |
| \S |
[^ \t\n\f\r] |
Gegenstück zu \s |
Quantoren
Es wird in den seltensten Fällen nach einzelnen Zeichen gesucht, sondern nach Mustern aus mehreren/vielen Zeichen. Die Anzahl der Zeichen
kann so angegeben werden:
| Quantor |
Bedeutung |
Beispiel |
matcht mit |
| ? |
Zeichen tritt einmal auf oder tritt nicht auf |
r"https?:" |
https: oder http: |
| * |
Zeichen tritt keinmal, einmal oder mehrmals auf |
r"shop\s*center" |
shopcenter oder shop center oder shop center |
| + |
Zeichen tritt mindestens einmal auf (einmal oder mehrmals) |
r"0,\d+" |
0,7 oder 0,314 oder 0,00301 |
Klammerschreibweise: Es gibt durchaus Fälle, wo die Verwendung von ?, * und + nicht präzise genug ist.
Hier steht dann die Klammerschreibweise für eine Bereichsangabe zur Verfügung.
Ein Beispiel: \d{2,5} bedeutet, mindestens 2 Ziffer, höchstens 5 Ziffern. Damit ergeben sich z.B. auch für ?, * und + andere Schreibweisen.
| Abkürzung |
Entsprechung |
Bedeutung |
| {n} |
{n,n} |
Zeichen tritt genau n-mal auf |
| {n,} |
|
Zeichen tritt mindestens n-mal auf |
| {,n} |
|
Zeichen tritt höchstens n-mal auf |
| ? |
{0,1} |
Zeichen tritt einmal auf oder tritt nicht auf |
| + |
{1,} |
Zeichen tritt mindestens einmal auf |
| * |
{0,} |
Zeichen tritt beliebig oft auf |
Alternativen
Eine Zeile des Logfiles vom Webserver Apache im "common"-Format sieht z.B. so aus:
127.0.0.1 - frank [10/Oct/2000:13:55:36 -0700] "GET /apache_pb.gif HTTP/1.0" 200 2326
D.h. der Zeitpunkt wird so angegeben: 10/Oct/2000:13:55:36. Dabei ist "Oct" die Abkürzung für Oktober.
Die Abkürzungen der anderen Monate sind: Jan, Feb, Mar, Apr, May, Jun, Jul, Aug, Sep, Oct, Nov, Dec.
Wenn man nun die Zeilen heraussuchen will, die von den Monaten September bis November sind, dann sieht die Regex so aus:
regex = r"Sep|Oct|Nov"
Allerdings wird die Regex nicht nur aus der Alternative bestehen, sodass man üblicherweise Klammern setzt.
regex = r"\d\d/(Sep|Oct|Nov)/20.."
Ankerpunkte
Wenn ein Muster in einer Zeile gesucht wird, kostet das deutlich mehr Zeit, als wenn die Regex "weiss",
wo sie beginnen muss. Wenn also die Regex mit dem Beginn der Zeile bzw. des Strings matcht und das in der Regex auch angegeben wird,
dann erhöht das die Performance beträchtlich. Um am Anfang der Zeile des Logfiles vom Apache (siehe letzter Punkt "Alternative")
nach der IP am Anfang zu suchen, schreibt man das so:
regex = r"^\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}"
Genauso sinnvoll ist es, wenn die Regex auf das Ende des Strings bzw. der Zeile passt. Dann schreibt man das so:
regex = r"\d+$"
Das bedeutet im Fall der Zeile des Logfiles, dass diese darauf geprüft wird, dass am Ende eine Zahl aus mindestens einer Ziffer steht.
Optionen
Optionen dienen dazu das Verhalten unserer Regex zu verändern. Optionen für die Regex sind in Python als Parameter mit Bitflags gelöst,
welche als extra Parameter übergeben werden. Dieser Parameter ist eine Zahl, bei der jedes Bit für eine Option steht. Diese Optionen sind im re-Modul
z.B. re.I oder re.X . Wenn mehrere Optionen übergeben werden sollen, können diese demzufolge mit dem ODER-Operator kombiniert werden (z.B. re.I | re.X)
Ein Beispielprogramm dazu:
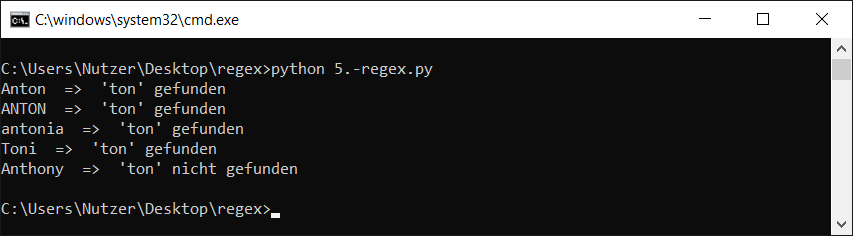
import re
liste = ["Anton", "ANTON", "antonia", "Toni", "Anthony"]
regex = r"ton"
for string in liste:
if (re.search(regex, string, flags=re.I)):
print(string, " => 'ton' gefunden")
else:
print(string, " => 'ton' nicht gefunden")
Der Aufruf sah dann bei mir so aus:
Ein Beispiel für die Option re.X ist im nächsten Punkt zu finden.
Teilausdrücke merken
Bis jetzt wurde immer das Muster als Ganzes betrachtet, entweder es hat gepasst (gematcht) oder eben nicht.
Die wahre Leistung entfalten die regulären Ausdrücke aber dann, wenn man auf beliebige Teile des Musters zugreifen kann.
Zitat (siehe Weblink 2):
Falls man den selben regulären Ausdruck mehrmals in seinem Skript verwenden will, ist es eine gute Idee, den Ausdruck zu kompilieren. ...
Kompilierte reguläre Ausdrücke sparen in der Regel nicht viel Rechenzeit, weil Python sowieso automatisch reguläre Ausdrücke kompiliert und zwischenspeichert,
auch wenn man sie mit re.search() oder re.match() aufruft.
Ein guter Grund dafür sie zu verwenden, besteht darin, die Definition und die Benutzung von regulären Ausdrücken zu trennen.
Es soll im Folgenden aus den Zeilen des Logfiles vom Webserver Apache die IP, das Login, das Datum und die Zeit herausgezogen werden.
Dazu wird als erstes die Zeile des Logfiles mit Hilfe einer Regex beschrieben. Nochmal die Beispiel-Zeile des Logfiles:
127.0.0.1 - frank [10/Oct/2000:13:55:36 -0700] "GET /apache_pb.gif HTTP/1.0" 200 2326
Man kann den Anfang dieser Zeile so beschreiben:
| 1. |
|
die IP-Adresse des Client |
\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3} |
11. |
|
ein Leerzeichen |
\s |
| 2. |
|
ein oder mehrere Leerzeichen |
\s+ |
12. |
|
eine Zahl, eventuell mit Minus |
-?\d+ |
| 3. |
|
ein Minus "-" |
- |
13. |
|
eine schließende Klammer "]" |
\] |
| 4. |
|
ein Leerzeichen |
\s |
14. |
|
ein Leerzeichen |
\s |
| 5. |
|
das Login |
\w+ |
15. |
|
ein Anführungszeichen |
\" |
| 6. |
|
ein Leerzeichen |
\s |
|
|
|
|
| 7. |
|
die öffnende Klammer "[" |
\[ |
|
|
mehr wird nicht gebraucht |
|
| 8. |
|
das Datum |
\d\d/.{3}/20\d\d |
|
|
|
|
| 9. |
|
ein Doppelpunkt ":" |
: |
|
|
|
|
| 10. |
|
die Zeit |
..:..:.. |
|
|
|
|
Damit ergibt sich als Regex zur Beschreibung für den Anfang einer solchen Zeile des Logfiles:
^\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}\s+-\s\w+\s\[\d\d/.{3}\/20\d\d:..:..:..\s-?\d+\]\s\"
Um jetzt die IP, das Login, das Datum und die Zeit heraus zu holen, verwenden wir benannte Gruppierungen. Hier wird ausschließlich
diese Schreibweise verwendet (siehe Weblink 3):
(?<name>subexpression)
Die Regex sieht dann so aus:
r"^(?P<ip>\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3})\s+-\s(?P<login>\w+)\s\[(?P<datum>\d\d\/.{3}\/20\d\d)\:(?P<zeit>..:..:..)\s-?\d+\]\s\""
Ein Beispielprogramm dazu:
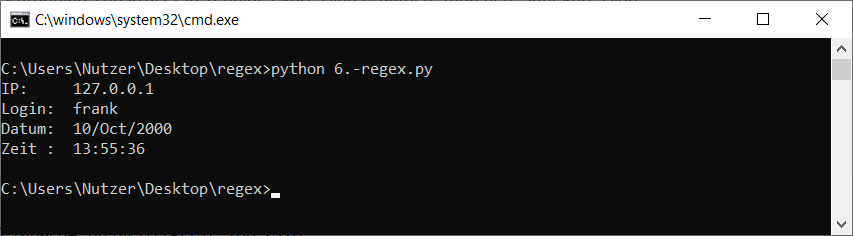
import re
zeile = '127.0.0.1 - frank [10/Oct/2000:13:55:36 -0700] "GET /apache_pb.gif HTTP/1.0" 200 2326'
regex = r"^(?P<ip>\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3})\s+-\s(?P<login>\w+)\s\[(?P<datum>\d\d\/.{3}\/20\d\d)\:(?P<zeit>..:..:..)\s-?\d+\]\s\""
match = re.match(regex, zeile)
if match:
print("IP: ", match['ip'])
print("Login: ", match['login'])
print("Datum: ", match['datum'])
print("Zeit : ", match['zeit'])
else:
print("matcht nicht")
Der Aufruf sah dann bei mir so aus:
Wem die Regex zu unübersichtlich ist, der hat ja die Möglichkeit, die Option re.X zu verwenden. Das Programm sieht bei mir so aus:
import re
zeile = '127.0.0.1 - frank [10/Oct/2000:13:55:36 -0700] "GET /apache_pb.gif HTTP/1.0" 200 2326'
regex = re.compile(r"""
^ # die Regex muss auf den Anfang der Zeile passen
(?P<ip>\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3})# die IP-Adresse des Client
\s+ # ein oder mehrere Leerzeichen
- # ein Minus "-"
\s # ein Leerzeichen
(?P<login>\w+) # das Login
\s # ein Leerzeichen
\[ # die öffnende Klammer "["
(?P<datum>\d\d/.{3}\/20\d\d) # das Datum
: # ein Doppelpunkt ":"
(?P<zeit>..:..:..) # die Zeit
\s # ein Leerzeichen
-?\d+ # eine Zahl, eventuell mit Minus
\] # eine schließende Klammer "]"
\s # ein Leerzeichen
\" # ein Anführungszeichen
""", re.X)
match = re.match(regex, zeile)
if match:
print("matcht")
print("IP: ", match['ip'])
print("Login: ", match['login'])
print("Datum: ", match['datum'])
print("Zeit : ", match['zeit'])
else:
print("matcht nicht")
Die Ausgabe ist natürlich die Gleiche wie im letzten Screenshot.
Gier
Bei der Verwendung von runden Klammern, um Teilausdrücke zu merken (siehe Punkt 9) kommt es häufig vor, dass mehrere Möglichkeiten gibt, die auf die geklammerten Ausdrücke
in der Regex passen. Damit ergibt sich die Frage, "welcher Teilausdruck wird dann durch die Regex gefunden?".
Der Text "42abcd42" soll mit der Regex "abcd?" durchsucht werden. Diese Regex passt sowohl auf "abc" als auch auf "abcd".
import re
# Dieser String soll mit dem regulärem Ausdruck durchsucht werden.
text = "42abcd42"
# Diese Regex passt sowohl auf "abc" als auch auf "abcd".
regex = "abcd?"
# Suchergebnis ausgeben
treffer = re.search(regex, text)
print(treffer.group(0)) # abcd
Wenn man dieses Miniprogramm ablaufen läßt, dann erhält man:

Da die Regex gierig ist, wird hier "abcd" und nicht "abc" ausgeben, obwohl "abc" ebenso passt.
Merke: die Regex findet von den passenden Ausdrücken immer den Ausdruck mit den meisten Zeichen! - man sagt auch: die Regex ist gierig.
Funktionen des Moduls 're' zur Nutzung der reulären Ausdrücke
Damit reguläre Ausdrücke genutzt werden können, liefert das re-Modul entsprechende Funktionen mit, die mit einer Regex umgehen können.
Es werden hier beispielhaft die Funktionen match, search, findall und split kurz erklärt.
Mit match lässt sich überprüfen, ob ein regulärer Ausdruck auf einen String passt.
Des weiteren lassen sich auch Werte mittels Capture-Gruppen extrahieren (siehe andere Beispiele)
import re
if re.match(r"[0-9]+", "42"):
print("Zahl erkannt")

Mit search lässt sich in einem String nach der ersten Sequenz suchen, auf die die Regex passt.
import re
suche = re.search(r"[0-9]+", "Die Antwort lautet 42.")
if suche:
# Erste Gruppe aus dem Objekt nehmen
print("Gefundene Zahl:", suche.group(0))

Mit findall kann man alle Sequenzen in einem String finden, auf die eine Regex passt.
Diese werden als Liste zurückgegeben.
import re
zahlen = re.findall(r"[0-9]+", "Einkaufszettel: 3 Birnen, 5 Äpfel und 4 Tomaten")
print("Gefundene Zahlen:", ", ".join(zahlen))

Mit split (wohlgemerkt: aus dem re-Modul) kann ein String an allen Stellen, wo ein Treffer ist, getrennt werden.
So lassen sich z.B. einfach Wörter zählen, wobei aufeinanderfolgende Leerzeichen ingoriert werden.
import re
text = "Ich bin ein Satz!"
liste = re.split(r" +", text)
print(len(liste), "Wörter")

Weblinks
- https://www.digitalocean.com/community/tutorials/python-raw-string
- https://www.python-kurs.eu/re_fortgeschrittene.php
- https://learn.microsoft.com/de-de/dotnet/standard/base-types/grouping-constructs-in-regular-expressions#named_matched_subexpression
zurück
© ERG Saalfeld - Moritz Thomae, Hans-Dietrich Kirmse 3.04.2023
| {kind=link}